Text-to-SQL for DuckDB database using Vanna, in 25 lines of code
Start ‘talking’ to your database using DuckDB in under 25 lines of code in Python

DuckDB is a popular open-source SQL database developed by MotherDuck. Launched in 2019, DuckDB is now used by companies, indie-hackers, and data professionals worldwide. It is renowned as a simple, fast, and feature-rich SQL database.
With the help of Vanna, you can now talk directly to your DuckDB database. This walkthrough will illustrate exactly how you can do so.
First a slight introduction to what exactly we will be building!


Getting started with Vanna
Installation
%pip install 'vanna[chromadb,duckdb]'You can use Vanna with any LLM and different Vector storage. Here is a snapshot of the configurations you can try:

Vanna allows users to use their hosted option or any local vector store and Large Language Model (LLM). This post will be showcasing how you can use both options.
Vanna Hosted
To use the Vanna hosted option you would need an API key and create a model on their site. Enter an email address and create a model here:
Next, fill in this next block of code:
api_key = # Your API key from https://vanna.ai/account/profile
vanna_model_name = # Your model name from https://vanna.ai/account/profile
vn = VannaDefault(model=vanna_model_name, api_key=api_key)Local using Ollama
You could alternatively use a local LLM using Ollama, the below code shows you exactly how to do so.
from vanna.ollama.ollama import Ollama
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, Ollama):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
Ollama.__init__(self, config=config)
vn = MyVanna(config={'model': 'duckdb-nsql'})Connecting to DuckDB
Next, you need to connect to DuckDB, you can feed in your DuckDB URL and other credentials like this. You can connect to your own database or you can use the StackOverFlow database found here.
Overview of the Dataset
The StackOverflow database contains information about the posts, tags, users, votes, etc on the popular question, answer website stackoverflow.com



Connection
You can connect to DuckDB by filling in this pattern URL for your database.
motherduck:[<database_name>]?motherduck_token=<token>&saas_mode=true
You need to replace the database name for a database in your DB and the token with your token.
#replace the url with the URL of your dB
vn.connect_to_duckdb(url='motherduck:[<database_name>]?motherduck_token=<token>&saas_mode=true')Training on SQL
You can use Vanna to train on Information_schema, DDL, SQL statements, and also documentation specific to your domain (It includes information not explicit in the database but you would give to a new data analytics trainee).
Training on Plan (Information Schema)
# The information schema query may need some tweaking depending on your database. This is a good starting point.
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
# This will break up the information schema into bite-sized chunks that can be referenced by the LLM
plan = vn.get_training_plan_generic(df_information_schema)
plan
# If you like the plan, then uncomment this and run it to train
vn.train(plan=plan)Training on DDL
# In duckDB the describe statement can fetch the DDL for any table
vn.train(ddl="DESCRIBE SELECT * FROM Stackoverflow.users;")Training on SQL statements
# here is an example of training on SQL statements
vn.train(
question="What are the top 10 users with highest amount of Badges?"
,sql="""SELECT UserId, COUNT(*) AS badge_count
FROM stackoverflow.main.badges
GROUP BY UserId
ORDER BY badge_count DESC
LIMIT 10
""")
# Another example
vn.train(
question="What is the difference in total answers for the user who answered the most answers and the user who answered the least questions?",
,sql="SELECT MAX(answer_count) - MIN(answer_count) AS difference
FROM (
SELECT OwnerUserId, COUNT(*) AS answer_count
FROM stackoverflow.main.posts
WHERE PostTypeId = 2
GROUP BY OwnerUserId
) AS answer_counts;
")
Training on Documentation
# You can feed in contextual information using documentation
vn.train(documentation="We call the user with the highest answers in a year the Grand master")
You can view your training data using vn.get_training_data()
Asking Questions
# vn.ask is runs these following functions in sequence, which can be run individually
# 1. vn.generate_ql
# 2. vn.run_sql
# 3. vn.generate_plotly_code
# 4. vn.get_plotly_figure
# this is how you can ask Vanna question's post training
vn.ask(question='Find the user with the highest amount of downvotes?' , visualize= False)
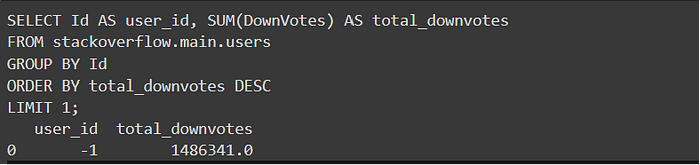
Lets ask a more challenging question, involving several tables.
# This question involves the badges and post table
vn.ask(vn.ask(question='Find the first post of the user with the highest amount of badges?', visualize=False)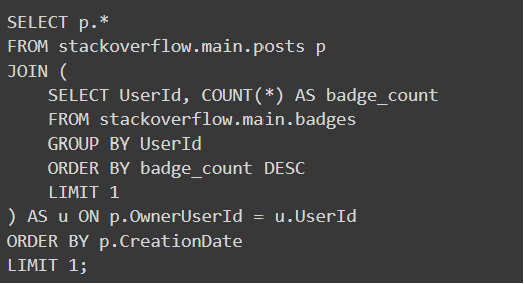
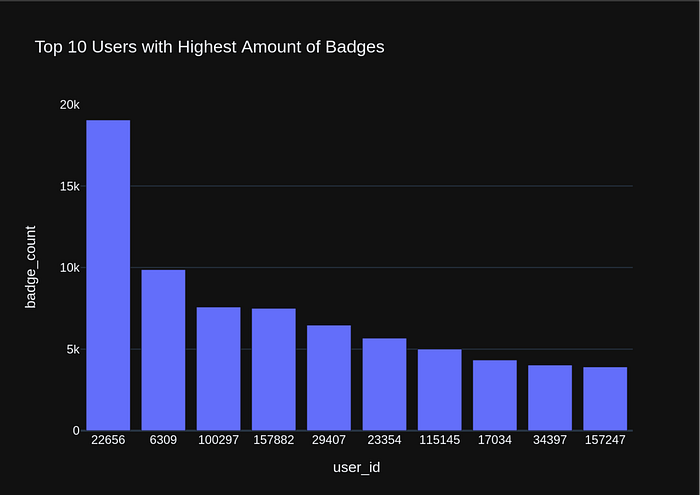
Now let us enable visualization, and see the results visualized in Plotly.
vn.ask('Find the top 10 users with the highest amount of Badges?')
Using the Flask App
Vanna comes with a built-in UI Flask app. Which can be launched inside a jupyter notebook or Python script.
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()Inside the Flask app you can ask questions, see visualizations, see training data & edit your training set.
