Chat with your CSV using DuckDB and Vanna.ai
Chat with datasets in CSV format

Vanna is a popular open-source Python library for text-to-SQL, it has over 7.2K stars on GitHub. By using the DuckDB csv importer you can actually began chatting with your comma-separated file (CSV).
Connecting to Vanna
You can use the Vanna hosted option which connects with ChatGPT. Alternatively you can use any other LLM and vector store like Llama 3.
Vanna hosted
To use the Vanna hosted option you would need an API key and create a model on their site. Enter an email address and create a model here:
api_key = # Your API key from https://vanna.ai/account/profile
vanna_model_name = # Your model name from https://vanna.ai/account/profile
vn = VannaDefault(model=vanna_model_name, api_key=api_key)Local LLM using Ollama
If you prefer to use a locally-running LLM, use this code instead:
from vanna.ollama.ollama import Ollama
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, Ollama):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
Ollama.__init__(self, config=config)
vn = MyVanna(config={'model': 'llama3b'})Connecting to a Database
For this post we would be using DuckDB locally and ingesting a CSV file.
#This is how you can connect to a DuckDB database
# The :memory: allows you connect to DuckDB in memory or locally
vn.connect_to_duckdb(url=':memory:')Ingesting CSV
DuckDB allows you import and read csv. For this post I would be using the WARN layoff dataset for California, you can find it here. You can also ingest multiple CSVs.
# running the CSV import command with the name of your file
# After downloading place the file in the same directory as the Python/Jupyter Script
# This will Create a Table with contents of the CSV and select it
vn.run_sql("""CREATE TABLE TABLE_NAME AS SELECT * FROM 'file_name.csv';
SELECT * FROM TABLE_NAME
""")Training
Vanna can aid in developing a RAG application which knows about the schema of your database.
Training on Plan
# The information schema query may need some tweaking depending on your database. This is a good starting point.
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
# This will break up the information schema into bite-sized chunks that can be referenced by the LLM
plan = vn.get_training_plan_generic(df_information_schema)
plan
# If you like the plan, then uncomment this and run it to train
vn.train(plan=plan)Training on DDL
# In duckDB the describe statement can fetch the DDL for any table
vn.train(ddl="DESCRIBE SELECT * FROM table_name")Training on Question/SQL Pair
# here is an example of training on SQL statements
# In the WARN Dataset number of workers are total laid off.
vn.train(
question="Calculate the total number of workers?"
,sql="""SELECT SUM(CAST("Number of Workers" AS INTEGER)) AS Total_Number_of_Workers
FROM WARN_DATASET
""")Training on Documentation
# We can use documentation to give explicit context that you would give to a data analyst
vn.train(documentation="The number of worker's column corresponds to people laid off")Chat
You can use the Vanna ask function to ask questions or launch the built in UI.
vn.ask("Which Company did the most amount of layoffs?", visualize=False)
You can use the following lines of code to launch the Flask App
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()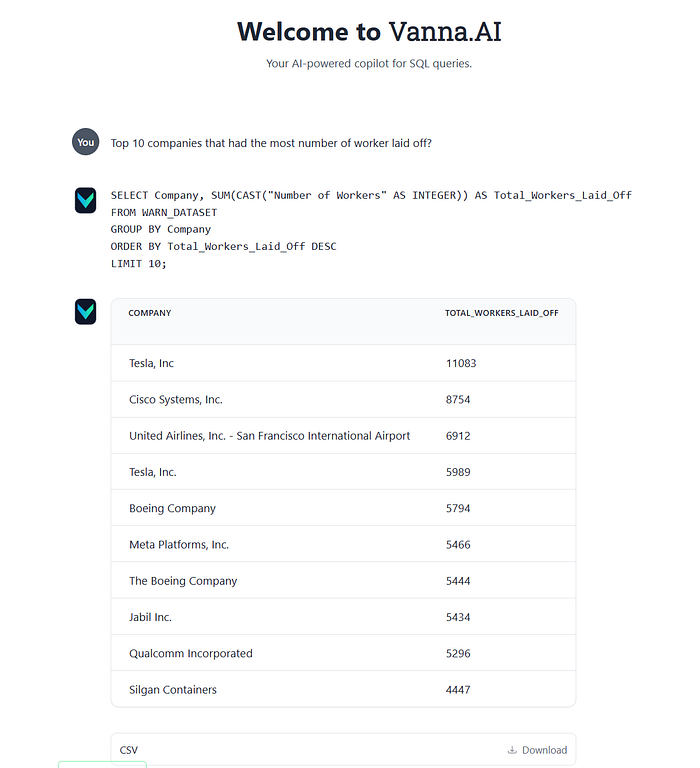
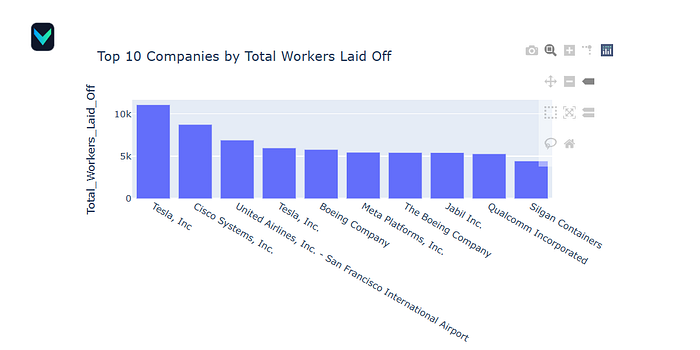
Thank you for reading!
