Building a Reliable Text-to-SQL Pipeline: A Step-by-Step Guide pt.2
Part 2, of developing reliable enterprise grade Text-to-SQL
This blog is the second part of creating a reliable text-to-SQL system. In the first part, I showed how to build a SQL agent with retry and reflection features from the ground up. You don’t need to have seen part one to follow along here — I hope you can still learn something useful, even if you’re using a different text-to-SQL tool.
Why do Text-to-SQL queries fail?
Before I start showing how to iteratively improve your SQL agent it is important to understand why do queries even fail? Here are the most common reasons.
- Invalid parsing: When you ask a large language model (LLM) to give you code, markdown, or any specific type of output, you need to process it correctly. To the model, everything it generates is just text tokens. However, it’s trained to use certain markers, like adding ```python or ```sql before structured code, so you know it's generating that kind of output. Sometimes, though, your parser might not handle it well, or the model might not include these markers correctly due to context limits, which can cause errors.
- Incorrect SQL Syntax: This often happens when you ask the model for SQL code for a specific database system, like Postgres, but you’re actually using a different one. It can also be an issue with different versions. LLMs are trained on lots of internet data, so they’re more familiar with popular SQL systems like Postgres, MySQL, and Oracle. It really helps to mention which SQL database you’re using in your prompt!
- Relevant Context not given/retrieved: LLMs are awesome, but they don’t know the details of your database! They have no idea what tables, columns, or row values you have. If you don’t give them the right information, they might make up things like table names, which can cause your query to fail. This is actually the most common reason why text-to-SQL queries don’t work, and it gets trickier when you’re dealing with bigger databases!
- LLMs can’t understand you: This is connected to the previous issue of missing context, but I wanted to highlight it separately. The right context should include more details — kind of like everything you’d give to a new analyst on their first day. This includes things like what all the abbreviations mean, how the company prefers to run analyses, and any “gotchas” or important things to know about how the data is stored and processed.
Now that it is explained on why queries fail, let see how to mitigate these issues!
Looking for expert(s) to build custom AI solutions for you?
Reach out here: https://tally.so/r/3x9bgo
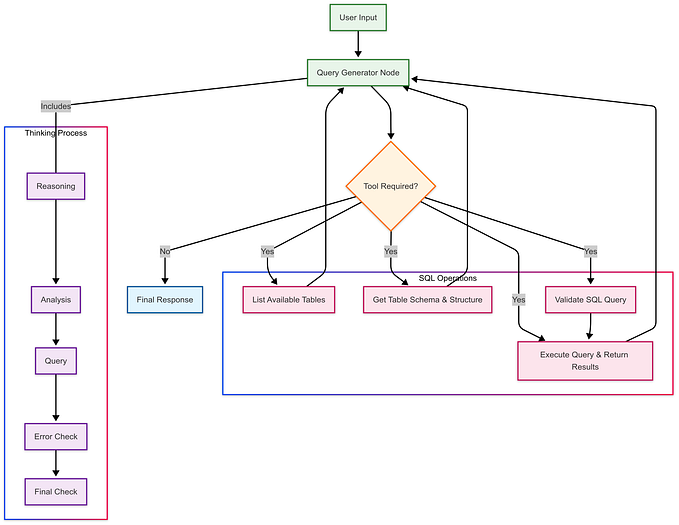
Fixing these problems
Here is how you should approach each of these
Incorrect Parsing
This is a “brute-forceable” problem, all you need to do is cover all the cases. Just a few if conditions to cover all of the wrong outputs you can get. Check what happens when the ending ``` is not present or when the SQL is in the middle of a lot of text.
Incorrect Syntax
These are steps you can take to mitigate this:
1. Explicitly add what version / DBMS you’re using in the prompt.
2. In the previous post, I used a error fixing agent. if you’re using something similar in your text to SQL solution, you can add common SQL version translations. Like how date parsing is different in Postgres etc.
Relevant Context not retrieved
To make a text-to-SQL tool work well with a large database, you need a “retriever.” This is a system that needs to be filled with examples of SQL queries you want to run. In my experience, the biggest reason a language model struggles to generate accurate queries is that it lacks enough training examples. Here’s how you can get your system ready to produce more reliable results.
For this blog, I used Qdrant as the retriever, but you can use any retriever that works for you. I also used the open-source Text-to-SQL dataset from gretelai, which is great because it already includes a variety of SQL queries and examples. If you’re building something for your own database, just make sure to add similar examples to your retriever:
1. question/SQL pairs
2. Metadata about tables columns
3. Use-case / domain specific information.
On the first attempt of the retriever, you will likely have some misses, but you can create feedback system, as explained later.
from qdrant_client import QdrantClient, models
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
import numpy as np
# Using OpenAI embedding but you can use other embedding models from HuggingFace
def get_embedding(text):
"""Get OpenAI embedding for text"""
response = openai_client.embeddings.create(
model="text-embedding-ada-002",
input=text
)
return response.data[0].embedding
# Initialize clients
# using in :memory: for this demo but you can host this on Qdrant cloud
qdrant = QdrantClient(":memory:") # Using in-memory storage for demo
openai_client = OpenAI()
# Collection names
# I decided to create three different collections to
sql_pairs_collection = "sql_question_pairs"
metadata_collection = "domain_metadata"
db_info_collection = "db_info"
# Create collections if they don't exist
collections = [
(sql_pairs_collection, "For storing SQL query and question pairs"),
(metadata_collection, "For storing domain/business knowledge"),
(db_info_collection, "For storing database schema and table information")
]
# This creates the collection
for collection_name, description in collections:
if not qdrant.collection_exists(collection_name):
qdrant.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE, on_disk=True)
)
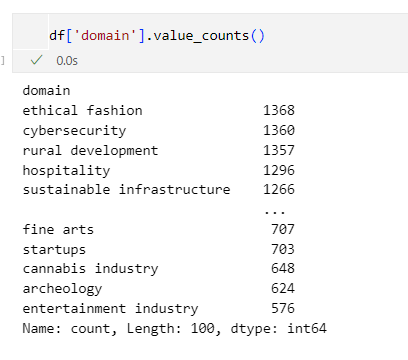
For a fair assessment I would create two sample datasets from this larger dataset. The train set would have 10 queries from every domain while the test set will have 5 (excluding those in the trainset).
#Creating a test train split!
train_df = df.groupby('domain').apply(lambda x: x.sample(n=min(len(x), 10))).reset_index(drop=True)
remaining_df = df[~df.index.isin(train_df.index)]
test_df = remaining_df.groupby('domain').apply(lambda x: x.sample(n=min(len(x), 5))).reset_index(drop=True)
print(f"Original dataset size: {len(df)}")
print(f"Training set size: {len(train_df)}")
print(f"Test set size: {len(test_df)}")
print("\nTraining samples per domain:")
print(train_df['domain'].value_counts())
print("\nTest samples per domain:")
print(test_df['domain'].value_counts())Next step is to “upsert” the trainset into the Qdrant collections!
# The vector for each is the SQL prompt (which is the query that user asks)
# The reason for doing so is that you want the RAG pipeline to be responsive to the
# user has entered. Also makes the retrieval more cohesive (all three collections grab
# context that is releavant to the query)
#gets all the tables mentioned
for _, row in train_df.iterrows():
domain = row['domain']
sql = row['sql']
# Extract table names from SQL using simple regex
# Look for words after FROM or JOIN
tables = re.findall(r'(?:FROM|JOIN)\s+([a-zA-Z_][a-zA-Z0-9_]*)', sql, re.IGNORECASE)
# Add unique tables to domain's set
if domain not in domain_tables:
domain_tables[domain] = set()
domain_tables[domain].update(tables)
for idx, row in train_df.iterrows():
# Generate embedding
prompt_embedding = get_embedding(row["sql_prompt"])
# Domain collection
domain_point = models.PointStruct(
id=idx,
vector=prompt_embedding,
payload={
"domain": row["domain"],
"domain_description": domain_tables[row['domain']]
}
)
qdrant.upsert(
collection_name="domain_metadata",
points=[domain_point]
)
# Database info collection
db_point = models.PointStruct(
id=idx,
vector=prompt_embedding,
payload={
"sql_context": row["sql_context"]
}
)
qdrant.upsert(
collection_name="db_info",
points=[db_point]
)
# SQL question pairs collection
sql_point = models.PointStruct(
id=idx,
vector=prompt_embedding,
payload={
"sql_prompt": row["sql_prompt"],
"sql": row["sql"]
}
)
qdrant.upsert(
collection_name="sql_question_pairs",
points=[sql_point]
)
print("Training data upserted into collections successfully")You can use any text2SQL system with this retriever, as long as you pass the retrieved context. So
def search_similar_examples(query_text, top_k=3):
"""
Search for similar examples across all collections using embedding similarity
Args:
query_text (str): The query text to search for
top_k (int): Number of results to return per collection
Returns:
Dictionary containing results from each collection with their payloads and scores
"""
# Generate embedding for query text
query_embedding = get_embedding(query_text)
collections = ["domain_metadata", "db_info", "sql_question_pairs"]
all_results = {}
# Search each collection
for collection in collections:
search_result = qdrant.search(
collection_name=collection,
query_vector=query_embedding,
limit=top_k
)
# Extract results for this collection
results = []
for scored_point in search_result:
results.append({
'payload': scored_point.payload,
'score': scored_point.score
})
all_results[collection] = results
return all_results
sql_system = # attach any AI LLM based system that takes in a query & context
context = search_similar_examples(query)
sql_system.query(query=query, relevant_context = str(context), db_engine=conn)Now that we have a retriever ready, we should measure how good it does with generating queries.
Using the test set we get these metrics!
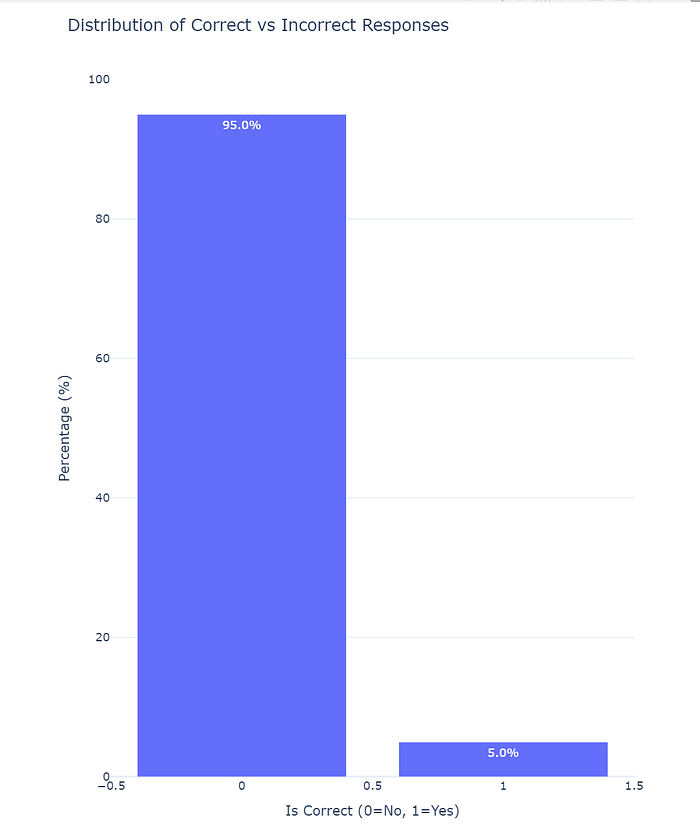
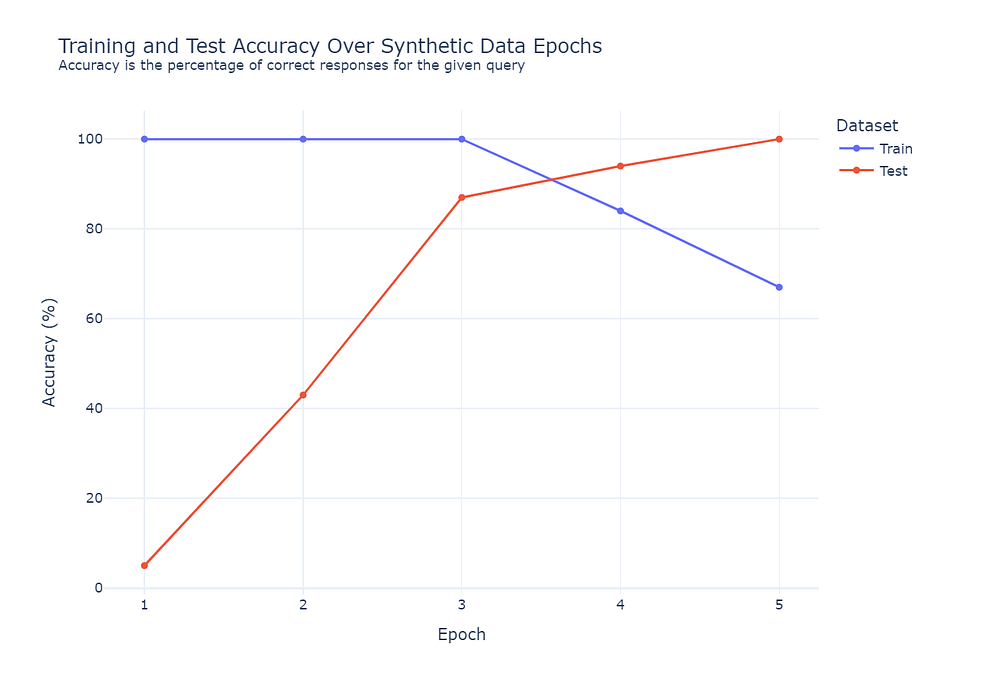
As expected the system did not perform as well on the test set. Which implies that asking the system anything out of context would not work well.
Before building a comprehensive solution let’s look at individual queries to understand the problem.


Looking at the above example a few things become clear, the system got confused between table names and columns. As the retrieved context shows that there are two tables' Satellites and SatelliteInfo . Overall, the query logic is 100% correct but it got two semantically similar table names wrong.


Once again logically the query is correct but the system used the developers table joined with smart_contracts, but the correct query directly queries the smart_contracts table.


This time the system’s mistake is that it does not know that location variable in program’s table has the location already marked as Asia. No need to individually mention every country.
In all three of these examples, the system was only wrong because the context was unable to give enough information for the correct answer. Most of the mistakes were due to not understanding what values are inside the db.
Solution Pipeline
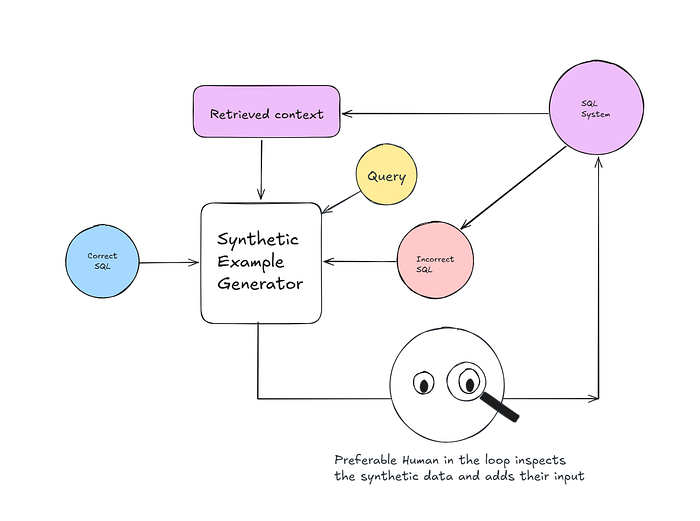
The solution is actually “simple”, the system fails because it lacks context for the correct SQL query. You can use a LM program to generate better context to be feed into the retriever. While a human can inspect or observe the whole process & be an editor to enhance the system.
Here is how you can create a LM program using DSPy to do this.
class sql_example_generator(dspy.Signature):
"""
A synthetic SQL example generator that takes a user query, correct SQL, incorrect SQL and context
to generate additional similar examples to improve the system's context.
The generator creates a new SQL/query pairs that maintain similar patterns but vary in complexity
and specific details.
You can use the retrieved context to see how the database is structured.
"""
user_query = dspy.InputField(desc="Original user query that describes what kind of SQL is needed")
correct_sql = dspy.InputField(desc="The correct SQL query for the user's request")
incorrect_sql = dspy.InputField(desc="An incorrect SQL query attempt")
retrieved_context = dspy.InputField(desc="The context information about tables and schema")
new_query = dspy.OutputField(desc="create one new query that maintains similar patterns but vary in complexity and specific details")
new_sql = dspy.OutputField(desc="create one new SQL that matches the new query")
sql_context_gen = dspy.ChainOfThought(sql_example_generator)Here are some synthetic examples generated



Adding this to the context let’s re-measure our accuracy on test set.
Note: Yes, technically this is training on test set, but unlike traditional ML where your data collection is limited, here you can synthetically create infinite similar examples.
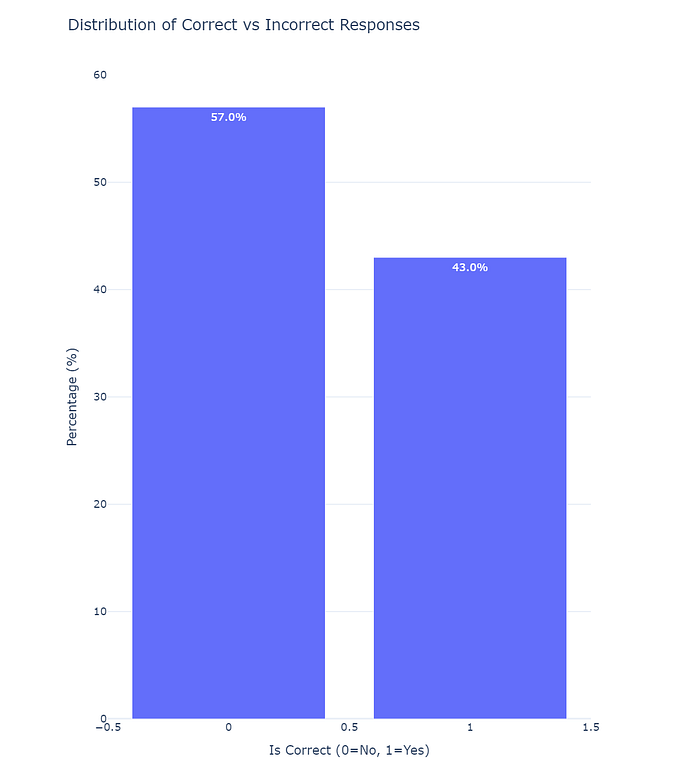
After one pass or epoch the number of correct queries is now 43%. Using the same process as before, you can augment with synthetic examples on queries that failed. After running a few epochs, this was the result.
Looking for expert(s) to build custom AI solutions for you?
Reach out here: https://tally.so/r/3x9bgo
Based on this data set the optimal amount of augmentation steps/epochs is around 3. This may vary depending on how “challenging” your database is for text to SQL.
Don’t forget to follow me & Firebird Technologies.