Build a text to SQL chatbot with Claude-Sonnet 3.5.
Text-to-SQL using Claude Sonnet 3.5, plus a benchmarking against GPT models

Anthropic has just unveiled its latest flagship model, Claude 3.5. This state-of-the-art model excels in understanding and generating human-like responses, making it ideal for a wide range of applications. In this post, we will demonstrate how you can build a text-to-SQL pipeline to interact with your database using Claude 3.5 and Vanna AI.
At the end I have also done a comparison on how Claude performs when compared with OpenAI models on SQL.


Getting Started
from vanna.vannadb.vannadb_vector import VannaDB_VectorStore
from vanna.base import VannaBase
from vanna.anthropic.anthropic_chat import Anthropic_Chat
class MyVanna(VannaDB_VectorStore, Anthropic_Chat):
def __init__(self, config=None):
MY_VANNA_MODEL = # Your model name from https://vanna.ai/account/profile
VannaDB_VectorStore.__init__(self, vanna_model=MY_VANNA_MODEL, vanna_api_key= #insert Vanna_API key, config=config)
Anthropic_Chat.__init__(self, config=config)
api_key = # insert your API key
# You can change models to any Anthropic model
# You can use Sonnet and Haiku but this post uses Opus
model = "claude-3.5-sonnet-20240620"
config = {'api_key':api_key,'model':model}
# Passes the configuration to MyVanna object
vn = MyVanna(config=config)Connecting to a Database
Vanna has built-in connectors for these 8 databases (you can connect to other database with a few additional lines of code):
- Postgres SQL
- Oracle
- DuckDB
- MySQL
- SQLite
- Big Query
- Snowflake
- Microsoft SQL
By looking at the documentation, you can figure out how to connect your specific database. For the purposes of this post, I would be connecting to DuckDB StackOverFlow Database. The database can found here!
#This is how you can connect to a DuckDB database
vn.connect_to_duckdb(url='motherduck:[<database_name>]?motherduck_token=<token>&saas_mode=true')Training
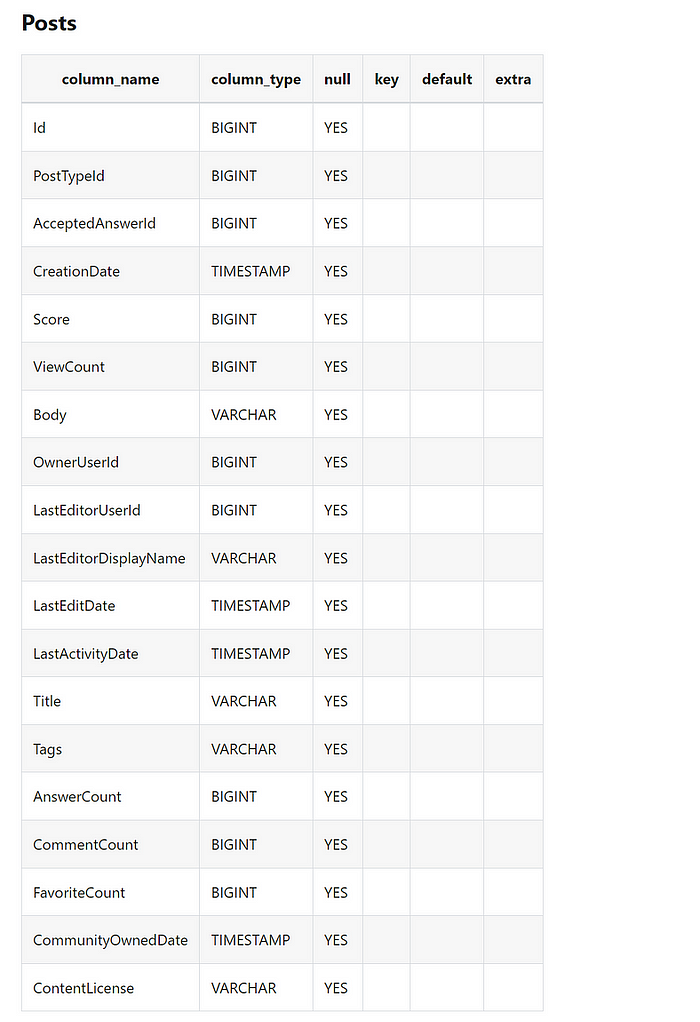


Training on Plan (Information Schema)
# The information schema query may need some tweaking depending on your database. This is a good starting point.
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")# This will break up the information schema into bite-sized chunks that can be referenced by the LLM
plan = vn.get_training_plan_generic(df_information_schema)
plan# If you like the plan, then uncomment this and run it to train
vn.train(plan=plan)Training on DDL
# In duckDB the describe statement can fetch the DDL for any table
vn.train(ddl="DESCRIBE SELECT * FROM Stackoverflow.users;")Training on SQL statements
# here is an example of training on SQL statements
vn.train(
question="What are the top 10 users with highest amount of Badges?"
,sql="""SELECT UserId, COUNT(*) AS badge_count
FROM stackoverflow.main.badges
GROUP BY UserId
ORDER BY badge_count DESC
LIMIT 10
""")
# Another example
vn.train(
question="What is the difference in total answers for the user who answered the most answers and the user who answered the least questions?",
,sql="SELECT MAX(answer_count) - MIN(answer_count) AS difference
FROM (
SELECT OwnerUserId, COUNT(*) AS answer_count
FROM stackoverflow.main.posts
WHERE PostTypeId = 2
GROUP BY OwnerUserId
) AS answer_counts;
")Training on Documentation
# You can feed in contextual information using documentation
vn.train(documentation="We call the user with the highest answers in a year the Grand master")You can view your training data using vn.get_training_data()
# vn.ask is runs these following functions in sequence, which can be run individually
# 1. vn.generate_ql
# 2. vn.run_sql
# 3. vn.generate_plotly_code
# 4. vn.get_plotly_figure# this is how you can ask Vanna question's post training
vn.ask('Find the top 10 users with the highest amount of Badges?')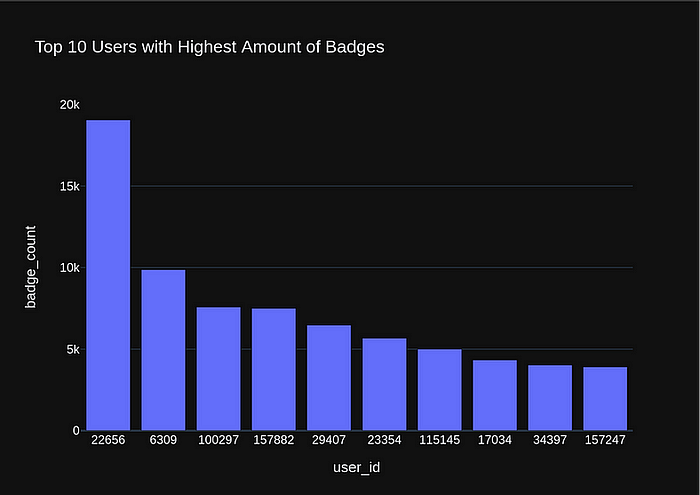
Using the Flask App
Vanna comes with a built-in UI Flask app. Which can be launched inside a jupyter notebook or Python script.
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()Benchmark
How does Claude Sonnet 3.5 compare to GPT 4o? We’ve compared them using our benchmarks. (Schema-only means Vanna was only trained on data definition language (DDL), and Schema-and-reference-sql means it was also trained on SQL question pairs.)
Schema-only
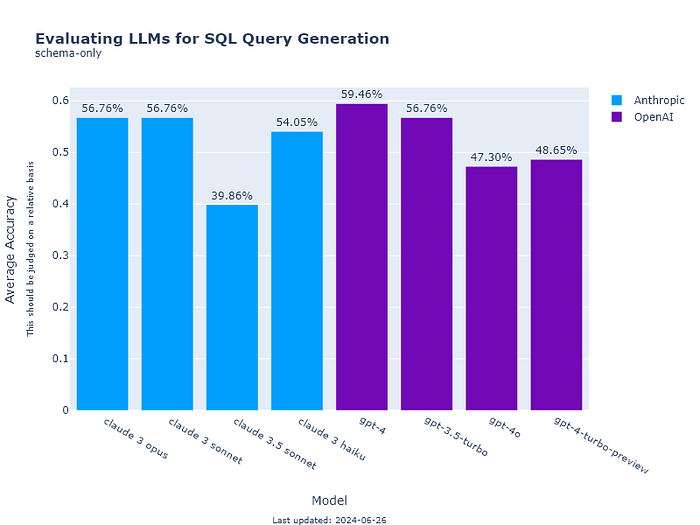
Claude sonnet 3.5 performs rather poorly compared with other LLMs when only trained on schema information. Which is odd.
Schema-and-reference-SQL
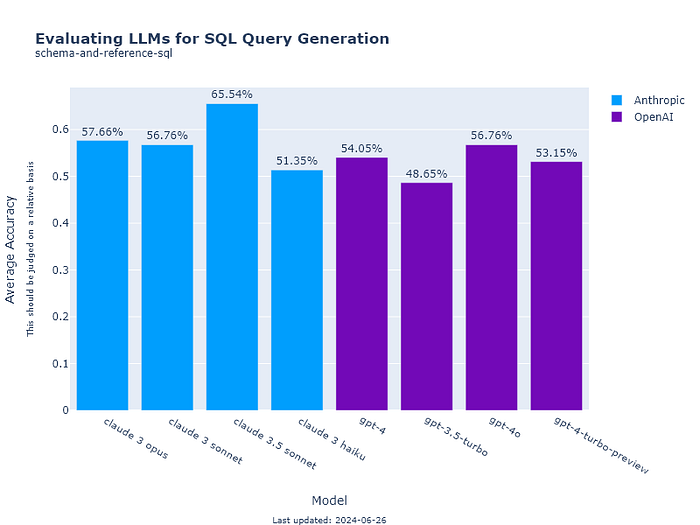
Rather shockingly, Claude-3.5 outperforms all other LLMs when trained on reference SQL and SQL-question pairs.
Average
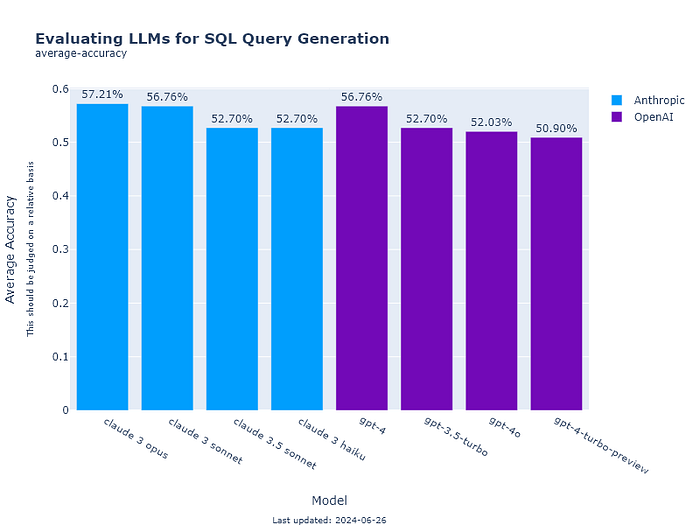
So, when taken an average of the two scores, Claude-Sonnet 3.5 performs similar range to GPT-4o.
Thank you for reading!
